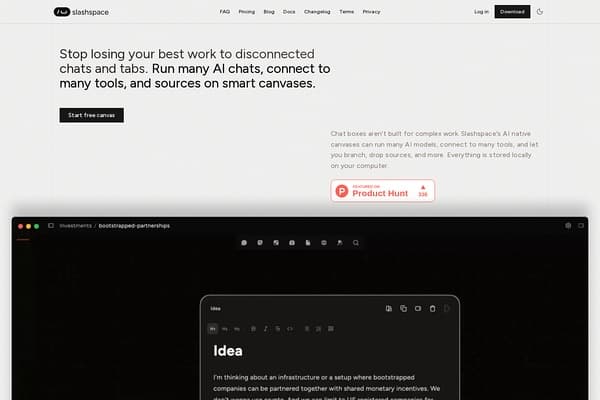
Slashspace
Revolutionize your AI chat experience with Slashspace's infinite canvas!
AI Productivity·freemium
Revolutionize image-text connections with OpenAI's CLIP.
OpenAI's CLIP is a groundbreaking AI model that merges visual and textual understanding. By employing contrastive learning methodologies, it can gauge the relevance of text associated with images. Its technology is pivotal for advancing areas such as machine learning, computer vision, and natural language processing. Researchers and developers can utilize CLIP for a multitude of purposes, from fine-tuning custom image-labeling systems to enhancing accessibility tools that bridge language barriers.
CLIP’s architecture leverages vast datasets to create rich embeddings, allowing the model to understand complex relationships between language and imagery. This makes it not only a powerful research tool but also a practical solution for industries looking to innovate their workflows, automate content moderation, or develop more intuitive user interfaces. As a repository on GitHub, it is easily accessible for those looking to integrate AI capabilities into their projects seamlessly.
OpenAI's CLIP is currently available for free on GitHub, allowing developers to implement and experiment with its capabilities without cost. Users can access the source code and documentation directly from the repository: https://github.com/openai/CLIP.
Pros
Cons
CLIP is primarily used for connecting images and text to improve predictive capabilities in various applications like search, content moderation, and creative tools.
CLIP learns through contrastive learning on large datasets of image-text pairs, allowing it to create meaningful connections between visual and textual data.
CLIP is free to use, accessible via its GitHub repository where you can download and implement it.
Yes, you can use CLIP for commercial projects, as it is open-source under the terms outlined in its repository.
Running CLIP effectively may require a decent GPU and familiarity with programming frameworks like PyTorch.
Revolutionize your AI chat experience with Slashspace's infinite canvas!
Transform your academic work with AI-powered citation and research tools.

Explore groundbreaking AI solutions with DeepMind's advanced models.